三、JUC:java.util.concurrent 3.1 集合 3.1.1 BlockingQueue 什么是阻塞队列?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时, 获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
阻塞队列提供了四种处理方法:
方法\处理方式
抛出异常
返回特殊值
一直阻塞
超时退出
插入方法
add(e)
offer(e)
put(e)
offer(e,time,unit)
移除方法
remove()
poll()
take()
poll(time,unit)
检查方法
element()
peek()
不可用
不可用
异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException(“Queue full”)异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。
返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元 素,如果没有则返回null
一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直 到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻 塞消费者线程,直到队列可用。
超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出
阻塞队列接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 BlockingQueue的核心方法: public interface BlockingQueue <E > extends Queue <E > boolean add (E e) boolean offer (E e) void put (E e) throws InterruptedException boolean offer (E e, long timeout, TimeUnit unit) throws InterruptedException ; E take () throws InterruptedException ; E poll (long timeout, TimeUnit unit) throws InterruptedException ; int remainingCapacity () boolean remove (Object o) public boolean contains (Object o) int drainTo (Collection<? super E> c) int drainTo (Collection<? super E> c, int maxElements) }
继承关系
TransferQueue
TransferQueue继承了BlockingQueue,并扩展了一些新方法。
BlockingQueue是指这样的一个队列:当生产者向队列添加元素但队列已满时,生产者会被阻塞;当消费者从队列移除元素但队列为空时,消费者会被阻塞。
TransferQueue则更进一步,生产者会一直阻塞直到所添加到队列的元素被某一个消费者所消费 (不仅仅是添加到队列里就完事)。新添加的transfer方法用来实现这种约束。顾名思义,阻塞就是发生在元素从一个线程transfer到另一个线程的过程中,它有效地实现了元素在线程之间的传递(以建立Java内存模型中的happens-before关系的方式)。 TransferQueue还包括了其他的一些方法:两个tryTransfer方法,一个是非阻塞的,另一个带 有timeout参数设置超时时间的。还有两个辅助方法hasWaitingConsumer()和getWaitingConsumerCount()。
实现类
ArrayBlockingQueue
DelayQueue
LinkedBlockingDeque
LinkedBlockingQueue
LinkedTransferQueue
PriorityBlockingQueue
SynchronousQueue
3.1.2 ArrayBlockingQueue ArrayBlockingQueue 是一个线程安全的、基于数组、有界的、阻塞的、FIFO 队列。试图向已满队列中放入元素会导致操作受阻塞;试图从空队列中提取元素将导致类似阻塞。
使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue;public class ArrayBlockingQueueDemo public static void main (String[] args) BlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(3 ,true ); Producer producer = new Producer(blockingQueue); Consumer consumer = new Consumer(blockingQueue); new Thread(producer).start(); new Thread(consumer).start(); } } class Producer implements Runnable private BlockingQueue<Integer> blockingQueue; private static int element = 0 ; public Producer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (element < 20 ) { System.out.println("生产元素:" +element); blockingQueue.put(element++); } } catch (Exception e) { System.out.println("生产者在等待空闲空间的时候发生异常!" ); e.printStackTrace(); } System.out.println("生产者终止了生产过程!" ); } } class Consumer implements Runnable private BlockingQueue<Integer> blockingQueue; public Consumer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (true ) { System.out.println("消费元素:" +blockingQueue.take()); } } catch (Exception e) { System.out.println("消费者在等待新产品的时候发生异常!" ); e.printStackTrace(); } System.out.println("消费者终止了消费过程!" ); } }
3.1.3 PriorityBlockingQueue PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级高的元素,是二叉树小堆的实现。
使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import java.util.Random;import java.util.concurrent.PriorityBlockingQueue;public class PriorityBlockingQueueTest public static void main (String[] args) throws InterruptedException PriorityBlockingQueue<PriorityElement> queue = new PriorityBlockingQueue<>(); for (int i = 0 ; i < 5 ; i++) { Random random=new Random(); PriorityElement ele = new PriorityElement(random.nextInt(10 )); queue.put(ele); } while (!queue.isEmpty()){ System.out.println(queue.take()); } } } class PriorityElement implements Comparable <PriorityElement > private int priority; PriorityElement(int priority) { this .priority = priority; } @Override public int compareTo (PriorityElement o) return priority >= o.getPriority() ? 1 : -1 ; } public int getPriority () return priority; } public void setPriority (int priority) this .priority = priority; } @Override public String toString () return "PriorityElement [priority=" + priority + "]" ; } }
3.1.4 DelayQueue DelayQueue 队列中每个元素都有个过期时间,并且队列是个优先级队列,当从队列获取元素时候,只有过期元素才会出队列。
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.concurrent.DelayQueue;import java.util.concurrent.Delayed;import java.util.concurrent.TimeUnit;public class DelayQueueTest public static void main (String[] args) throws InterruptedException Item item1 = new Item("item1" , 5 , TimeUnit.SECONDS); Item item2 = new Item("item2" ,10 , TimeUnit.SECONDS); Item item3 = new Item("item3" ,15 , TimeUnit.SECONDS); DelayQueue<Item> queue = new DelayQueue<>(); queue.put(item1); queue.put(item2); queue.put(item3); System.out.println("begin time:" + LocalDateTime.now().format(DateTimeFormatter.ISO_LOCAL_DATE_TIME)); for (int i = 0 ; i < 3 ; i++) { Item take = queue.take(); System.out.format("name:{%s}, time:{%s}\n" ,take.name, LocalDateTime.now().format(DateTimeFormatter.ISO_DATE_TIME)); } } } class Item implements Delayed private long time; String name; public Item (String name, long time, TimeUnit unit) this .name = name; this .time = System.currentTimeMillis() + (time > 0 ? unit.toMillis(time): 0 ); } @Override public long getDelay (TimeUnit unit) return time - System.currentTimeMillis(); } @Override public int compareTo (Delayed o) Item item = (Item) o; long diff = this .time - item.time; if (diff <= 0 ) { return -1 ; }else { return 1 ; } } @Override public String toString () return "Item{" + "time=" + time + ", name='" + name + '\'' + '}' ; } }
3.1.5 LinkedBlockingQueue LinkedBlockingQueue 是一个基于单向链表的、范围任意的(其实是有界的)、FIFO 阻塞队列。访问 与移除操作是在队头进行,添加操作是在队尾进行,并分别使用不同的锁进行保护,只有在可能涉及多 个节点的操作才同时对两个锁进行加锁。
队列是否为空、是否已满仍然是通过元素数量的计数器(count)进行判断的,由于可以同时在队头、 队尾并发地进行访问、添加操作,所以这个计数器必须是线程安全的,这里使用了一个原子类 AtomicInteger ,这就决定了它的容量范围是: 1 – Integer.MAX_VALUE。
使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;import java.util.concurrent.LinkedBlockingDeque;import java.util.concurrent.LinkedBlockingQueue;public class ArrayBlockingQueueDemo public static void main (String[] args) BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>(); Producer producer = new Producer(blockingQueue); Consumer consumer = new Consumer(blockingQueue); new Thread(producer).start(); new Thread(consumer).start(); } } class Producer implements Runnable private BlockingQueue<Integer> blockingQueue; private static int element = 0 ; public Producer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (element < 20 ) { System.out.println("生产元素:" +element); blockingQueue.put(element++); } } catch (Exception e) { System.out.println("生产者在等待空闲空间的时候发生异常!" ); e.printStackTrace(); } System.out.println("生产者终止了生产过程!" ); } } class Consumer implements Runnable private BlockingQueue<Integer> blockingQueue; public Consumer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (true ) { System.out.println("消费元素:" +blockingQueue.take()); } } catch (Exception e) { System.out.println("消费者在等待新产品的时候发生异常!" ); e.printStackTrace(); } System.out.println("消费者终止了消费过程!" ); } }
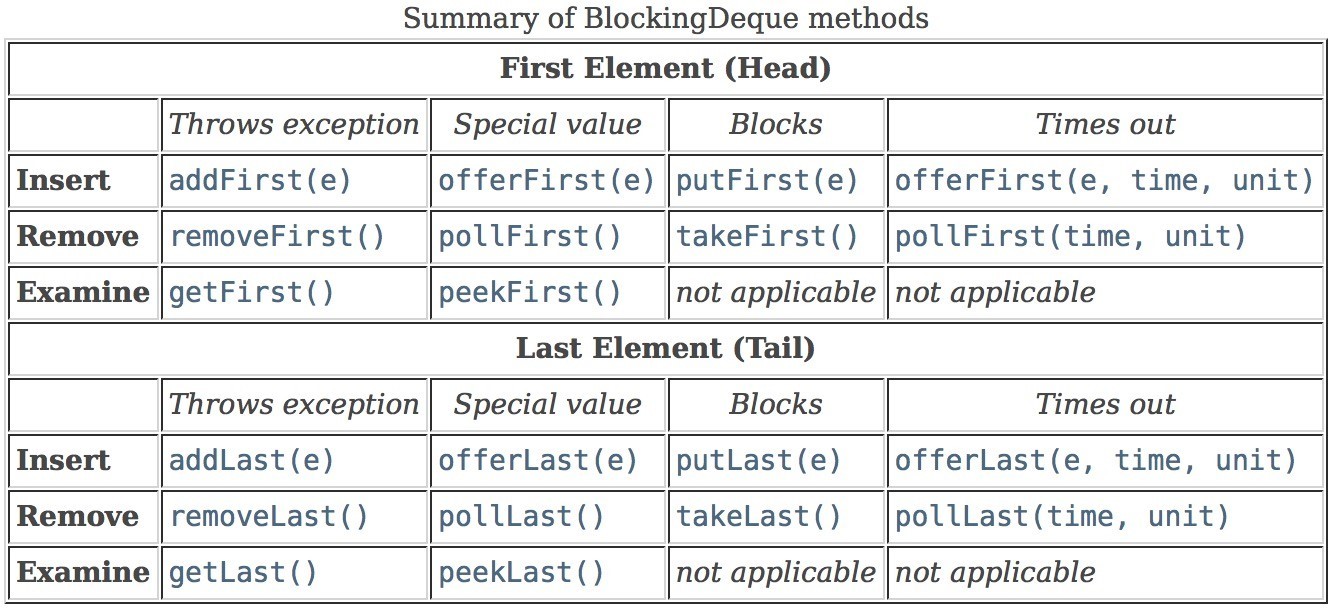
3.1.6 LinkedBlockingDeque LinkedBlockingDeque 是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两 端插入和移出元素。双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的 竞争。相比其他的阻塞队列,LinkedBlockingDeque多了addFirst,addLast,offerFirst, offerLast,peekFirst,peekLast等方法,以First单词结尾的方法,表示插入,获取(peek)或移 除双端队列的第一个元素。以Last单词结尾的方法,表示插入,获取或移除双端队列的后一个元素。 另外插入方法add等同于addLast,移除方法remove等效于removeFirst。在初始化 LinkedBlockingDeque时可以初始化队列的容量,用来防止其再扩容时过渡膨胀。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingDeque;public class LinkedBlockingQueueDemo public static void main (String[] args) BlockingQueue<Integer> blockingQueue = new LinkedBlockingDeque<Integer>(); Producer producer = new Producer(blockingQueue); Consumer consumer = new Consumer(blockingQueue); new Thread(producer).start(); new Thread(consumer).start(); } } class Producer implements Runnable private BlockingQueue<Integer> blockingQueue; private static int element = 0 ; public Producer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (element < 20 ) { System.out.println("生产元素:" +element); blockingQueue.put(element++); } } catch (Exception e) { System.out.println("生产者在等待空闲空间的时候发生异常!" ); e.printStackTrace(); } System.out.println("生产者终止了生产过程!" ); } } class Consumer implements Runnable private BlockingQueue<Integer> blockingQueue; public Consumer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (true ) { System.out.println("消费元素:" +blockingQueue.take()); } } catch (Exception e) { System.out.println("消费者在等待新产品的时候发生异常!" ); e.printStackTrace(); } System.out.println("消费者终止了消费过程!" ); } }
3.1.7 SynchronousQueue SynchronousQueue 是一个没有数据缓冲的BlockingQueue,生产者线程对其的插入操作put必须等待 消费者的移除操作take,反过来也一样。
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import java.util.concurrent.*;public class SynchronousQueueDemo public static void main (String[] args) BlockingQueue<Integer> blockingQueue = new SynchronousQueue<>(); Producer producer = new Producer(blockingQueue); Consumer consumer = new Consumer(blockingQueue); new Thread(producer).start(); new Thread(consumer).start(); } } class Producer implements Runnable private BlockingQueue<Integer> blockingQueue; private static int element = 0 ; public Producer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (element < 20 ) { System.out.println("生产元素:" +element); blockingQueue.put(element++); } } catch (Exception e) { System.out.println("生产者在等待空闲空间的时候发生异常!" ); e.printStackTrace(); } System.out.println("生产者终止了生产过程!" ); } } class Consumer implements Runnable private BlockingQueue<Integer> blockingQueue; public Consumer (BlockingQueue<Integer> blockingQueue) this .blockingQueue = blockingQueue; } public void run () try { while (true ) { Thread.sleep(1000l ); System.out.println("消费元素:" +blockingQueue.take()); } } catch (Exception e) { System.out.println("消费者在等待新产品的时候发生异常!" ); e.printStackTrace(); } System.out.println("消费者终止了消费过程!" ); } }
3.1.8 LinkedTransferQueue LinkedTransferQueue 是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列 LinkedTransferQueue多了tryTransfer和transfer方法。
使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import java.util.concurrent.*;public class LinkedTransferQueueTest public static void main (String[] args) LinkedTransferQueue<Integer> blockingQueue = new LinkedTransferQueue<Integer>(); Producer producer = new Producer(blockingQueue); Consumer consumer = new Consumer(blockingQueue); new Thread(producer).start(); new Thread(consumer).start(); } } class Producer implements Runnable private LinkedTransferQueue<Integer> linkedTransferQueue; private static int element = 0 ; public Producer (LinkedTransferQueue<Integer> linkedTransferQueue) this .linkedTransferQueue = linkedTransferQueue; } public void run () try { while (element < 20 ) { System.out.println("生产元素:" +element); linkedTransferQueue.put(element++); } } catch (Exception e) { System.out.println("生产者在等待空闲空间的时候发生异常!" ); e.printStackTrace(); } System.out.println("生产者终止了生产过程!" ); } } class Consumer implements Runnable private LinkedTransferQueue<Integer> linkedTransferQueue; public Consumer (LinkedTransferQueue<Integer> linkedTransferQueue) this .linkedTransferQueue = linkedTransferQueue; } public void run () try { while (true ) { Thread.sleep(1000l ); System.out.println("消费元素:" +linkedTransferQueue.take()); } } catch (Exception e) { System.out.println("消费者在等待新产品的时候发生异常!" ); e.printStackTrace(); } System.out.println("消费者终止了消费过程!" ); } }
3.1.9 ConcurrentHashMap HashMap容量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public HashMap (int initialCapacity, float loadFactor) if (initialCapacity < 0 ) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this .loadFactor = loadFactor; this .threshold = tableSizeFor(initialCapacity); }
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等 操作,所以非常消耗性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 final HashMap<String, String> map = new HashMap<String, String>(2 );Thread t = new Thread(new Runnable() { @Override public void run () for (int i = 0 ; i < 10000 ; i++) { new Thread(new Runnable() { @Override public void run () map.put(UUID.randomUUID().toString(), "" ); } }, "kaikeba" + i).start(); } } }, "kaikeba" ); t.start(); t.join();
效率低下的 HashTable 容器 HashTable 容器使用 syncronized来保证线程安全,但在线程竞争激烈的情况下 HashTable 的效率 非常低下。因为当一个线程访问 HashTable 的同步方法时,其他线程访问 HashTable 的同步方法 时,可能会进入阻塞或轮询状态。如线程 1 使用 put 进行添加元素,线程 2 不但不能使用 put 方 法添加元素,并且也不能使用 get 方法来获取元素,所以竞争越激烈效率越低。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.util.Iterator; import java.util.Map; import java.util.concurrent.ConcurrentHashMap;public class ConcurrentHashMapTest public static void main (String[] args) Map<String, String> map = new ConcurrentHashMap<String, String>(); map.put("key1" , "1" ); map.put("key2" , "2" ); map.put("key3" , "3" ); map.put("key4" , "4" ); Iterator<String> it = map.keySet().iterator(); while (it.hasNext()) { String key = it.next(); System.out.println(key + "," + map.get(key)); } } }
3.1.10 ConcurrentSkipListMap JDK1.6时,为了对高并发环境下的有序Map提供更好的支持,J.U.C新增了一个 ConcurrentNavigableMap接口,ConcurrentNavigableMap很简单,它同时实现了NavigableMap和 ConcurrentMap接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 import java.util.Map;import java.util.concurrent.ConcurrentNavigableMap; import java.util.concurrent.ConcurrentSkipListMap;public class ConcurrentSkipListMapTest public static void main (String[] args) ConcurrentSkipListMap<String, Contact> map = new ConcurrentSkipListMap<>(); Thread threads[]=new Thread[25 ]; int counter=0 ; for (char i='A' ; i<'Z' ; i++) { Task0 task=new Task0(map, String.valueOf(i)); threads[counter]=new Thread(task); threads[counter].start(); counter++; } for (int i=0 ; i<25 ; i++) { try { threads[i].join(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.printf("Size of the map: %d\n" ,map.size()); Map.Entry<String, Contact> element; Contact contact; element=map.firstEntry(); contact=element.getValue(); System.out.printf("First Entry: %s: %s\n" ,contact. getName(),contact.getPhone()); element=map.lastEntry(); contact=element.getValue(); System.out.printf("Last Entry: %s: %s\n" ,contact. getName(),contact.getPhone()); System.out.printf("Submap from A1996 to B1002: \n" ); ConcurrentNavigableMap<String, Contact> submap=map. subMap("A1996" , "B1001" ); do { element=submap.pollFirstEntry(); if (element!=null ) { contact=element.getValue(); System.out.printf("%s: %s\n" ,contact.getName(),contact. getPhone()); } } while (element!=null ); } } class Contact private String name; private String phone; public Contact (String name, String phone) this .name = name; this .phone = phone; } public String getName () return name; } public String getPhone () return phone; } } class Task0 implements Runnable private ConcurrentSkipListMap<String, Contact> map; private String id; public Task0 (ConcurrentSkipListMap<String, Contact> map, String id) this .id = id; this .map = map; } @Override public void run () for (int i = 0 ; i < 1000 ; i++) { Contact contact = new Contact(id, String.valueOf(i + 1000 )); map.put(id + contact.getPhone(), contact); } } }
3.1.11 ConcurrentSkipListSet ConcurrentSkipListSet ,是JDK1.6时J.U.C新增的一个集合工具类,它是一种有序的SET类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import java.util.concurrent.ConcurrentSkipListSet;public class ConcurrentSkipListSetTest public static void main (String[] args) ConcurrentSkipListSet<Contact1> set = new ConcurrentSkipListSet<> (); Thread threads[]=new Thread[25 ]; int counter=0 ; for (char i='A' ; i<'Z' ; i++) { Task1 task=new Task1(set, String.valueOf(i)); threads[counter]=new Thread(task); threads[counter].start(); counter++; } for (int i=0 ; i<25 ; i++) { try { threads[i].join(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.printf("Size of the set: %d\n" ,set.size()); Contact1 contact; contact=set.first(); System.out.printf("First Entry: %s: %s\n" ,contact. getName(),contact.getPhone()); contact=set.last(); System.out.printf("Last Entry: %s: %s\n" ,contact. getName(),contact.getPhone()); } } class Contact1 implements Comparable <Contact1 > private String name; private String phone; public Contact1 (String name, String phone) this .name = name; this .phone = phone; } public String getName () return name; } public String getPhone () return phone; } @Override public int compareTo (Contact1 o) return name.compareTo(o.name); } } class Task1 implements Runnable private ConcurrentSkipListSet<Contact1> set; private String id; public Task1 (ConcurrentSkipListSet<Contact1> set, String id) this .id = id; this .set = set; } @Override public void run () for (int i = 0 ; i < 100 ; i++) { Contact1 contact = new Contact1(id, String.valueOf(i + 100 )); set.add(contact); } } }
3.1.12 CopyOnWriteArrayList Copy-On-Write 简称COW,是一种用于程序设计中的优化策略。
其基本思路是,从一开始大家都在共享 同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并 发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
什么是CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前 容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素 之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读, 而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读 和写不同的容器。
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在 开发的时候需要注意一下内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个 对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候 会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用 的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有 可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制 更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是 10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。 数据一致性问题。CopyOnWrite容器只能保证数据的终一致性,不能保证数据的实时一致性。所以如 果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import java.util.Arrays;import java.util.List;import java.util.concurrent.CopyOnWriteArrayList;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit;class ReadThread implements Runnable private List<Integer> list; public ReadThread (List<Integer> list) this .list = list; } @Override public void run () System.out.print("size:=" +list.size()+",::" ); for (Integer ele : list) { System.out.print(ele + "," ); } System.out.println(); } } class WriteThread implements Runnable private List<Integer> list; public WriteThread (List<Integer> list) this .list = list; } @Override public void run () this .list.add(9 ); } } public class TestCopyOnWriteArrayListTest private void test () List<Integer> tempList = Arrays.asList(new Integer [] {1 ,2 }); CopyOnWriteArrayList<Integer> copyList = new CopyOnWriteArrayList<> (tempList); ExecutorService executorService = Executors.newFixedThreadPool(10 ); executorService.execute(new ReadThread(copyList)); executorService.execute(new WriteThread(copyList)); executorService.execute(new WriteThread(copyList)); executorService.execute(new WriteThread(copyList)); executorService.execute(new ReadThread(copyList)); executorService.execute(new WriteThread(copyList)); executorService.execute(new ReadThread(copyList)); executorService.execute(new WriteThread(copyList)); try { TimeUnit.SECONDS.sleep(5 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("copyList size:" +copyList.size()); } public static void main (String[] args) new TestCopyOnWriteArrayList().test(); } }
3.1.13 CopyOnWriteArraySet CopyOnWriteArraySet相对CopyOnWriteArrayList用来存储不重复的对象,是线程安全的。虽然继承了AbstractSet类,但CopyOnWriteArraySet与HashMap 完全不同,内部是用 CopyOnWriteArrayList实现的,实现不重复的特性也是直接调用CopyOnWriteArrayList的方法实现 的,感觉加的有用的函数就是eq函数判断对象是否相同
3.2 原子操作类 在并发编程中很容易出现并发安全的问题,有一个很简单的例子就是多线程更新变量i=1,比如多个线程 执行i++操作,就有可能获取不到正确的值,而这个问题,常用的方法是通过Synchronized进行控制 来达到线程安全的目的。但是由于synchronized是采用的是悲观锁策略,并不是特别高效的一种解决方案。实际上,在J.U.C下的atomic包提供了一系列的操作简单,性能高效,并能保证线程安全的类去 更新基本类型变量,数组元素,引用类型以及更新对象中的字段类型。atomic包下的这些类都是采用的 是乐观锁策略去原子更新数据,在java中则是使用CAS操作具体实现。
3.2.1 原子基本数据类型 原子更新基本类型
AtomicBoolean:以原子更新的方式更新boolean;
AtomicInteger:以原子更新的方式更新Integer;
AtomicLong:以原子更新的方式更新Long;
AtomicInteger常用的方法:
addAndGet(int delta) :以原子方式将输入的数值与实例中原本的值相加,并返回后的结 果;
incrementAndGet() :以原子的方式将实例中的原值进行加1操作,并返回终相加后的结果;
getAndSet(int newValue):将实例中的值更新为新值,并返回旧值;
getAndIncrement():以原子的方式将实例中的原值加1,返回的是自增前的旧值;
1 2 3 public final int getAndIncrement () return unsafe.getAndAddInt(this , valueOffset, 1 ); }
可以看出,该方法实际上是调用了unsafe实例的getAndAddInt方法,unsafe实例的获取时通过 UnSafe类的静态方法getUnsafe获取:
1 private static final Unsafe unsafe = Unsafe.getUnsafe();
Unsafe类在sun.misc包下,Unsafer类提供了一些底层操作,atomic包下的原子操作类的也主要是通 过Unsafe类提供的compareAndSwapInt,compareAndSwapLong等一系列提供CAS操作的方法来进行实现。
atomicInteger借助了UnSafe提供的CAS操作能够保证数据更新的时候是线程安全的,并且由于CAS是 采用乐观锁策略,因此,这种数据更新的方法也具有高效性。
AtomicLong的实现原理和AtomicInteger一致,只不过一个针对的是long变量,一个针对的是int变 量。而boolean变量的更新类AtomicBoolean类是怎样实现更新的呢?核心方法是 compareAndSet t方 法,
其源码如下:
1 2 3 4 5 public final boolean compareAndSet (boolean expect, boolean update) int e = expect ? 1 : 0 ; int u = update ? 1 : 0 ; return unsafe.compareAndSwapInt(this , valueOffset, e, u); }
可以看出,compareAndSet方法的实际上也是先转换成0,1的整型变量,然后是通过针对int型变量的 原子更新方法compareAndSwapInt来实现的。可以看出atomic包中只提供了对boolean,int ,long这 三种基本类型的原子更新的方法,参考对boolean更新的方式,原子更新char,double,float也可以采 用类似的思路进行实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class Main public static void main (String[] args) throws InterruptedException AtomicInteger ai = new AtomicInteger(); List<Thread> list = new ArrayList<>(); for (int i = 0 ; i < 10 ; i++) { Thread t = new Thread(new Accumlator(ai), "thread-" + i); list.add(t); t.start(); } for (Thread t : list) { t.join(); } System.out.println(ai.get()); } static class Accumlator implements Runnable private AtomicInteger ai; Accumlator(AtomicInteger ai) { this .ai = ai; } @Override public void run () for (int i = 0 , len = 1000 ; i < len; i++) { ai.incrementAndGet(); } } } }
3.2.2 原子数组 atomic包下提供能原子更新数组中元素的类有:
AtomicIntegerArray:原子更新整型数组中的元素;
AtomicLongArray:原子更新长整型数组中的元素;
AtomicReferenceArray:原子更新引用类型数组中的元素
这几个类的用法一致,就以AtomicIntegerArray来总结下常用的方法:
addAndGet(int i, int delta):以原子更新的方式将数组中索引为i的元素与输入值相加;
getAndIncrement(int i):以原子更新的方式将数组中索引为i的元素自增加1;
compareAndSet(int i, int expect, int update):将数组中索引为i的位置的元素进行更新
可以看出,AtomicIntegerArray与AtomicInteger的方法基本一致,只不过在AtomicIntegerArray 的方法中会多一个指定数组索引位i。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import java.util.concurrent.atomic.AtomicIntegerArray;public class AtomicIntegerArrayTest public static void main (String[] args) AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10 ); atomicIntegerArray.set(9 ,10 ); System.out.println("Value: " + atomicIntegerArray.get(9 ) + "默认值:" + atomicIntegerArray.get(0 )); System.out.println("数组长度:" + atomicIntegerArray.length()); atomicIntegerArray.set(0 ,10 ); System.out.println("Value: " + atomicIntegerArray.get(0 )); System.out.println("Value: " + atomicIntegerArray.addAndGet(5 ,10 )); Boolean bool = atomicIntegerArray.compareAndSet(5 ,10 ,30 ); System.out.println("结果值: " + atomicIntegerArray.get(5 ) + " Result: " + bool); System.out.println("下标为5的值为:" + atomicIntegerArray.decrementAndGet(5 )); System.out.println("下标为5的值为:" + atomicIntegerArray.get(5 )); Integer result2 = atomicIntegerArray.getAndAdd(5 ,5 ); System.out.println("下标为5的值为:" + result2); System.out.println("下标为5的值为:" + atomicIntegerArray.get(5 )); System.out.println("下标为1的值为:" + atomicIntegerArray.getAndDecrement(1 )); System.out.println("下标为1的值为:" + atomicIntegerArray.get(1 )); System.out.println("下标为2的值为:" + atomicIntegerArray.getAndIncrement(2 )); System.out.println("下标为2的值为:" + atomicIntegerArray.get(2 )); System.out.println("下标为3的值为:" + atomicIntegerArray.getAndSet(3 ,50 )); System.out.println("下标为3的值为:" + atomicIntegerArray.get(3 )); System.out.println("下标为4的值为:" + atomicIntegerArray.incrementAndGet(4 )); System.out.println("下标为4的值为:" + atomicIntegerArray.get(4 )); } }
并发测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import java.util.concurrent.atomic.AtomicIntegerArray;public class AtomicIntegerArrayTest2 static AtomicIntegerArray arr = new AtomicIntegerArray(10 ); public static class AddThread implements Runnable public void run () for (int k = 0 ; k < 10 ; k++) arr.getAndIncrement(k % arr.length()); } } public static void main (String[] args) throws InterruptedException Thread[] ts = new Thread[10 ]; for (int k = 0 ; k < 10 ; k++) { ts[k] = new Thread(new AddThread()); } for (int k = 0 ; k < 10 ; k++) { ts[k].start(); } for (int k = 0 ; k < 10 ; k++) { ts[k].join(); } System.out.println(arr); } }
3.2.3 原子引用类型 如果需要原子更新引用类型变量的话,为了保证线程安全,atomic也提供了相关的类:
AtomicReference
AtomicStampedReference
AtomicMarkableReference
AtomicReference的引入是为了可以用一种类似乐观锁的方式操作共享资源,在某些情景下以提升性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class AtomicReferenceTest public static void main (String[] args) throws InterruptedException AtomicReference<Integer> ref = new AtomicReference<>(new Integer(1000 )); List<Thread> list = new ArrayList<>(); for (int i = 0 ; i < 1000 ; i++) { Thread t = new Thread(new Task(ref), "Thread-" + i); list.add(t); t.start(); } for (Thread t : list) { t.join(); } System.out.println(ref.get()); } } class Task implements Runnable private AtomicReference<Integer> ref; Task(AtomicReference<Integer> ref) { this .ref = ref; } @Override public void run () for (; ; ) { Integer oldV = ref.get(); if (ref.compareAndSet(oldV, oldV + 1 )) break ; } } }
该案例并没有使用锁,是使用自旋+CAS的无锁操作保证共享变量的线程安全。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private static class Pair <T > final T reference; final int stamp; private Pair (T reference, int stamp) this .reference = reference; this .stamp = stamp; } static <T> Pair<T> of (T reference, int stamp) { return new Pair<T>(reference, stamp); } } private volatile Pair<V> pair; public AtomicStampedReference (V initialRef, int initialStamp) pair = Pair.of(initialRef, initialStamp); } }
解决ABA问题,引入了AtomicStampedReference。
AtomicStampedReference可以给引用加上版本号,追踪引用的整个变化过程,如: A -> B -> C -> D - > A,通过AtomicStampedReference,可以知道,引用变量中途被更改了3 次。
但是,有时候,我们并不关心引用变量更改了几次,只关心是否更改过,就有了 AtomicMarkableReference:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class AtomicMarkableReference <V > private static class Pair <T > final T reference; final boolean mark; private Pair (T reference, boolean mark) this .reference = reference; this .mark = mark; } static <T> Pair<T> of (T reference, boolean mark) { return new Pair<T>(reference, mark); } } private volatile Pair<V> pair; public AtomicMarkableReference (V initialRef, boolean initialMark) pair = Pair.of(initialRef, initialMark); } }
3.2.4 原子更新字段类型 如果需要更新对象的某个字段,并在多线程的情况下,能够保证线程安全,atomic同样也提供了相应的 原子操作类:
AtomicIntegeFieldUpdater:原子更新整型字段类;
AtomicLongFieldUpdater:原子更新长整型字段类;
AtomicReferenceFieldUpdater:
原子更新引用字段类型;
要想使用原子更新字段需要两步操作:
原子更新字段类都是抽象类,只能通过静态方法 newUpdater 来创建一个更新器,并且需要设置想 要更新的类和属性;
更新类的属性必须使用 public volatile 进行修饰;
字段必须是volatile类型的,在线程之间共享变量时保证立即可见
字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的 关系一致。也就是说调用者能够直接操作对象字段,那么就可以反射进行原子操作。
对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
只能是实例变量,不能是类变量,也就是说不能加static关键字。
只能是可修改变量,不能使final变量,因为final的语义就是不可修改。
对于AtomicIntegerFieldUpdater和AtomicLongFieldUpdater只能修改int/long类型的字 段,不能修改其包装类型(Integer/Long)。如果要修改包装类型就需要使用 AtomicReferenceFieldUpdater。
这几个类提供的方法基本一致,以AtomicIntegerFieldUpdater为例来看看具体的使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;public class AtomicIntegerFieldUpdaterTest private static AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age"); public static void main (String[] args) User user = new User("conan" , 10 ); System.out.println(a.getAndIncrement(user)); System.out.println(a.get(user)); } public static class User private String name; public volatile int age; public User (String name, int age) this .name = name; this .age = age; } public String getName () return name; } public int getAge () return age; } } }
从示例中可以看出,创建 AtomicIntegerFieldUpdater 是通过它提供的静态方法进行创建, getAndAdd 方法会将指定的字段加上输入的值,并且返回相加之前的值。user对象中age字段原值为 1,加5之后,可以看出user对象中的age字段的值已经变成了6。
3.3 锁:Lock java.util.concurrent.locks 包,该包提供了一系列基础的锁工具,用以对synchronizd、wait、 notify等进行补充、增强。 juc-locks锁框架中一共就三个接口:Lock、Condition、ReadWriteLock。
3.3.1 ReentrantLock ReentrantLock叫做可重入锁,指的是线程可以重复获取同一把锁,或者说该锁支持一个线程对资源的 重复加锁。同时该锁还支持获取锁的公平性和非公平性选择,锁的公平性是指,在绝对时间上,先对锁 获取的请求一定先被满足,也就是等待时间长的那个线程优先获得,可以说,锁的获取是顺序的,即 符合FIFO规则。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 final boolean nonfairTryAcquire (int acquires) final Thread current = Thread.currentThread(); int c = getState(); if (c == 0 ) { if (compareAndSetState(0 , acquires)) { setExclusiveOwnerThread(current); return true ; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0 ) throw new Error("Maximum lock count exceeded" ); setState(nextc); return true ; } return false ; }
成功获取锁的线程再次获取锁,只是增加了同步状态值,在释放同步转态时,相应的减少同步状态值, 实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 protected final boolean tryRelease (int releases) int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) throw new IllegalMonitorStateException(); boolean free = false ; if (c == 0 ) { free = true ; setExclusiveOwnerThread(null ); } setState(c); return free; }
公平锁和非公平锁的测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import org.junit.Test;import java.util.ArrayList; import java.util.Collection;import java.util.Collections; import java.util.List;import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock;public class ReentrantLockTest private static Lock fairLock = new ReentrantLockMine(true ); private static Lock unfairLock = new ReentrantLockMine(false ); @Test public void unfair () throws InterruptedException testLock("unfair lock" , unfairLock); } @Test public void fair () throws InterruptedException testLock("fair lock" , fairLock); } private void testLock (String type, Lock lock) throws InterruptedException System.out.println(type); for (int i = 0 ; i < 5 ; i++) { Thread thread = new Thread(new Job(lock)){ public String toString () return getName(); } }; thread.setName("" + i); thread.start(); } Thread.sleep(11000 ); } private static class Job implements Runnable private Lock lock; public Job (Lock lock) this .lock = lock; } public void run () for (int i = 0 ; i < 2 ; i++) { lock.lock(); try { Thread.sleep(1000 ); System.out.println("获取锁的当前线程[" + Thread.currentThread().getName() + "], 同步队列中的线程" + ((ReentrantLockMine)lock).getQueuedThreads() + "" ); } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } } } } private static class ReentrantLockMine extends ReentrantLock public ReentrantLockMine (boolean fair) super (fair); } @Override protected Collection<Thread> getQueuedThreads () List<Thread> arrayList = new ArrayList<Thread> (super .getQueuedThreads()); Collections.reverse(arrayList); return arrayList; } } }
非公平锁的获取,只要获取了同步状态就可以获取锁,有可能导致饥饿现象,但是非公平锁,线程的切 换比较少,更高效。
重入
synchronized可重入,因为加锁和解锁自动进行,不必担心后是否释放锁;ReentrantLock也 可重入,但加锁和解锁需要手动进行,且次数需一样,否则其他线程无法获得锁。
实现
synchronized是JVM实现的、而ReentrantLock是JDK实现的。说白了就是,是操作系统来实现, 还是用户自己敲代码实现。
性能
在 Java 的 1.5 版本中,synchronized 性能不如 SDK 里面的 Lock,但 1.6 版本之后, synchronized 做了很多优化,将性能追了上来。
功能
ReentrantLock锁的细粒度和灵活度,优于synchronized。 ReentrantLock不同点一:可在构造函数中指定是公平锁还是非公平锁,而synchronized只能是非公平锁
1 private static final ReentrantLock reentrantLock = new ReentrantLock(true );
ReentrantLock不同点二:可以避免死锁问题,因为它可以非阻塞地获取锁。如果尝试获取 锁失败,并不进入阻塞状态,而是直接返回false,这时候线程不用阻塞等待,可以先去做其他事情。 所以不会造成死锁。
tryLock还支持超时。调用tryLock时没有获取到锁,会等待一段时间,如果线程在一段时间之内还是 没有获取到锁,不是进入阻塞状态,而是throws InterruptedException,那这个线程也有机会释放 曾经持有的锁,这样也能破坏死锁不可抢占条件。
1 boolean tryLock (long time, TimeUnit unit)
ReentrantLock不同点三:提供能够中断等待锁机制。
synchronized 的问题是,持有锁 A 后,如果尝试获取锁 B 失败,那么线程就进入阻塞状态,一旦 发生死锁,就没有任何机会来唤醒阻塞的线程。
但如果阻塞状态的线程能够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤 醒它,那它就有机会释放曾经持有的锁 A。ReentrantLock可以用lockInterruptibly方法来实现。
ReentrantLock不同点四:可以用J.U.C包中的Condition实现分组唤醒需要等待的线程。而 synchronized只能notify或者notifyAll。
3.3.2 LockSupport LockSupport类,是JUC包中的一个工具类,定义了一组静态方法,提供基本的线程阻塞和唤醒功 能,是构建同步组件的基础工具,用来创建锁和其他同步类的基本线程阻塞原语。
假设现在需要实现一种FIFO类型的独占锁,可以把这种锁看成是ReentrantLock的公平锁简单版本, 且是不可重入的,就是说当一个线程获得锁后,其他等待线程以FIFO的调度方式等待获取锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import java.util.Queue; import java.util.concurrent.ConcurrentLinkedQueue; import java.util.concurrent.atomic.AtomicBoolean;import java.util.concurrent.locks.LockSupport; class FIFOMutex private final AtomicBoolean locked = new AtomicBoolean(false ); private final Queue<Thread> waiters = new ConcurrentLinkedQueue<>(); public void lock () Thread current = Thread.currentThread(); waiters.add(current); while (waiters.peek() != current || !locked.compareAndSet(false ,true )){ LockSupport.park(); } waiters.remove(); } public void unlock () locked.set(false ); LockSupport.unpark(waiters.peek()); } } public class TestFIFOMutex public static void main (String[] args) throws InterruptedException FIFOMutex mutex = new FIFOMutex(); MyThread a1 = new MyThread("a" , mutex); MyThread a2 = new MyThread("b" , mutex); MyThread a3 = new MyThread("c" , mutex); a1.start(); a2.start(); a3.start(); a1.join(); a2.join(); a3.join(); System.out.println("Finished" ); } } class MyThread extends Thread private String name; private FIFOMutex mutex; private static int count; public MyThread (String name, FIFOMutex mutex) this .name = name; this .mutex = mutex; } @Override public void run () for (int i = 0 ; i < 20 ; i++) { mutex.lock(); count++; System.out.println("thread:" +Thread.currentThread().getName()+" name:" + name + " count:" + count); mutex.unlock(); } } }
上述FIFOMutex类的实现中,当判断锁已被占用时,会调用 LockSupport.park(this) 方法,将当前 调用线程阻塞;当使用完锁时,会调用 LockSupport.unpark(waiters.peek()) 方法将等待队列中 的队首线程唤醒。
park 方法是会响应中断的,但是不会抛出异常。(也就是说如果当前调用线程被中断,则会立即 返回但不会抛出中断异常)
park 的重载方法 park(Object blocker),会传入一个blocker对象,所谓Blocker对象,其实 就是当前线程调用时所在调用对象(如上述示例中的FIFOMutex对象)。该对象一般供监视、诊断 工具确定线程受阻塞的原因时使用。
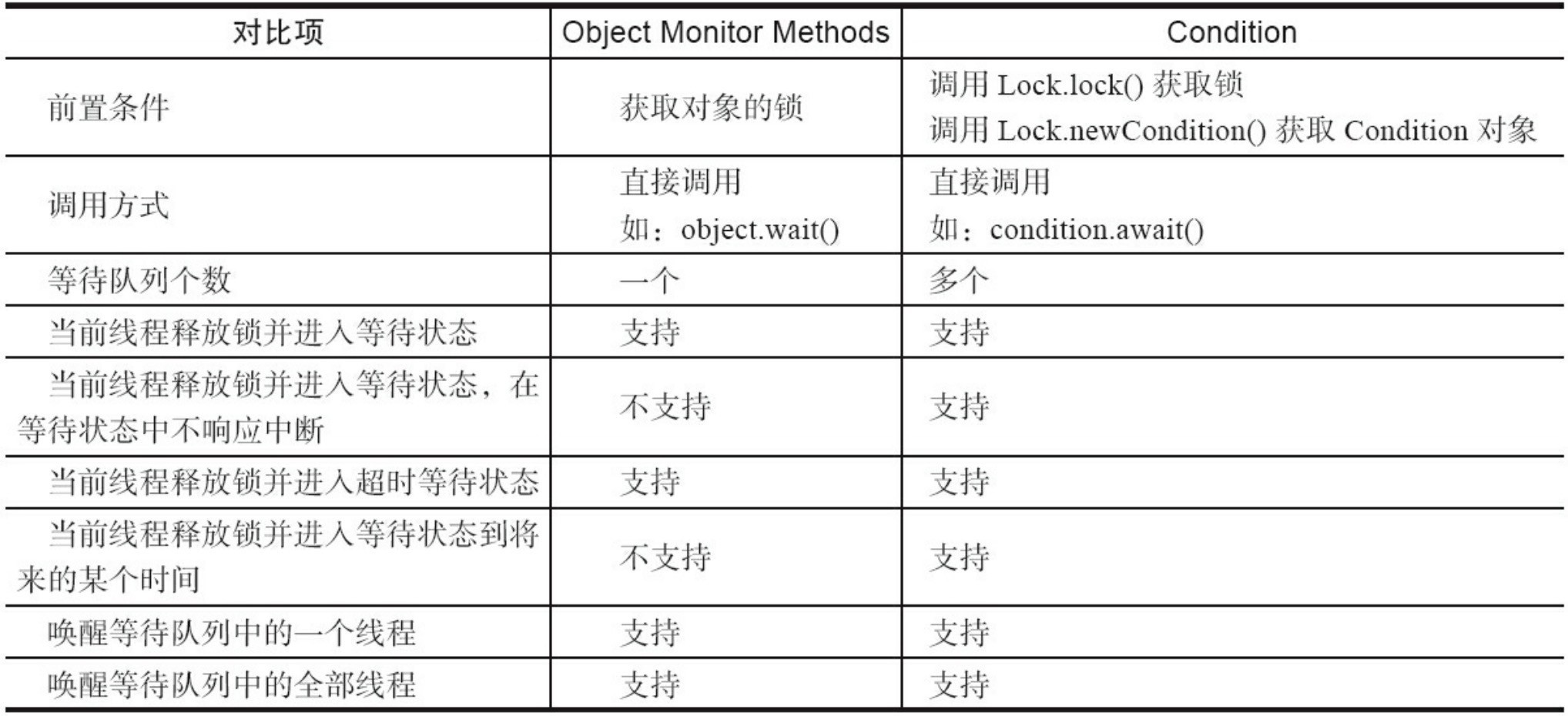
3.3.3 Condition 在没有Lock之前,我们使用synchronized来控制同步,配合Object的wait()、wait(long timeout)、notify()、以及notifyAll 等方法可以实现等待/通知模式。
Condition 将 Object 监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便 通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set(wait-set)。其中, Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。
条件(也称为条件队列 或条件变量)为线程提供了一个含义,以便在某个状态条件现在可能为 true 的另一个线程通知它之前,一直挂起该线程(即让其“等待”)。因为访问此共享状态信息发生在不同 的线程中,所以它必须受保护,因此要将某种形式的锁与该条件相关联。等待提供一个条件的主要属性 是:以原子方式 释放相关的锁,并挂起当前线程,就像 Object.wait 做的那样。
Condition 实例实质上被绑定到一个锁上。要为特定 Lock 实例获得 Condition 实例,请使用其 newCondition() 方法。
await():造成当前线程在接到信号或被中断之前一直处于等待状态。
await(long time, TimeUnit unit) :造成当前线程在接到信号、被中断或到达指定等待时 间之前一直处于等待状态。
awaitNanos(long nanosTimeout) :造成当前线程在接到信号、被中断或到达指定等待时间 之前一直处于等待状态。返回值表示剩余时间,如果在nanosTimesout之前唤醒,那么返回值 = nanosTimeout - 消耗时间,如果返回值 <= 0 ,则可以认定它已经超时了。
awaitUninterruptibly() :造成当前线程在接到信号之前一直处于等待状态。【注意:该方法对中断不敏感】。
awaitUntil(Date deadline) :造成当前线程在接到信号、被中断或到达指定后期限之前一 直处于等待状态。如果没有到指定时间就被通知,则返回true,否则表示到了指定时间,返回返 回false。
signal() :唤醒一个等待线程。该线程从等待方法返回前必须获得与Condition相关的锁。
signalAll() :唤醒所有等待线程。能够从等待方法返回的线程必须获得与Condition相关的 锁。
Condition是一种广义上的条件队列。他为线程提供了一种更为灵活的等待/通知模式,线程在调用 await方法后执行挂起操作,直到线程等待的某个条件为真时才会被唤醒。Condition必须要配合锁一 起使用,因为对共享状态变量的访问发生在多线程环境下。一个Condition的实例必须与一个Lock绑 定,因此Condition一般都是作为Lock的内部实现。
源码探索 获取一个Condition必须要通过Lock的newCondition()方法。该方法定义在接口Lock下,返回的结果 是绑定到此 Lock 实例的新 Condition 实例。
1 2 3 public class ConditionObject implements Condition , java .io .Serializable }
等待队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class ConditionObject implements Condition , java .io .Serializable private static final long serialVersionUID = 1173984872572414699L ; private transient Node firstWaiter; private transient Node lastWaiter; public ConditionObject () }
从上面代码可以看出Condition拥有首节点(firstWaiter),尾节点(lastWaiter)。
当前线程调用await()方法,将会以当前线程构造成一个节点(Node),并将节点加入到该队列的尾 部。
Condition的队列结构比CLH同步队列的结构简单些,新增过程较为简单只需要将原尾节点的 nextWaiter指向新增节点,然后更新lastWaiter即可。
等待
当从await()方法返回时,当前线程一定是获取了Condition相的锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public final void await () throws InterruptedException if (Thread.interrupted()) throw new InterruptedException(); Node node = addConditionWaiter(); int savedState = fullyRelease(node); int interruptMode = 0 ; while (!isOnSyncQueue(node)) { LockSupport.park(this ); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0 ) break ; } if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null ) unlinkCancelledWaiters(); if (interruptMode != 0 ) reportInterruptAfterWait(interruptMode); }
此段代码的逻辑是: 首先将当前线程新建一个节点同时加入到等待队列中,然后释放当前线程持有的同步状态。
加入条件队列(addConditionWaiter())源码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private Node addConditionWaiter () Node t = lastWaiter; if (t != null && t.waitStatus != Node.CONDITION) { unlinkCancelledWaiters(); t = lastWaiter; } Node node = new Node(Thread.currentThread(), Node.CONDITION); if (t == null ) firstWaiter = node; else t.nextWaiter = node; lastWaiter = node; return node; }
该方法主要是将当前线程加入到Condition条件队列中。当然在加入到尾节点之前会清除所有状态不为 Condition的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 final int fullyRelease (Node node) boolean failed = true ; try { int savedState = getState(); if (release(savedState)) { failed = false ; return savedState; } else { throw new IllegalMonitorStateException(); } } finally { if (failed) node.waitStatus = Node.CANCELLED; } }
isOnSyncQueue(Node node):如果一个节点刚开始在条件队列上,现在在同步队列上获取锁则返回 true。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 final boolean isOnSyncQueue (Node node) if (node.waitStatus == Node.CONDITION || node.prev == null ) return false ; if (node.next != null ) return true ; return findNodeFromTail(node); }
unlinkCancelledWaiters():负责将条件队列中状态不为Condition的节点删除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private void unlinkCancelledWaiters () Node t = firstWaiter; Node trail = null ; while (t != null ) { Node next = t.nextWaiter; if (t.waitStatus != Node.CONDITION) { t.nextWaiter = null ; if (trail == null ) firstWaiter = next; else trail.nextWaiter = next; if (next == null ) lastWaiter = trail; } else trail = t; t = next; } }
通知
调用Condition的signal()方法,将会唤醒在等待队列中等待长时间的节点(条件队列里的首节 点),在唤醒节点前,会将节点移到同步队列中。
1 2 3 4 5 6 7 8 9 public final void signal () if (!isHeldExclusively()) throw new IllegalMonitorStateException(); Node first = firstWaiter; if (first != null ) doSignal(first); }
该方法首先会判断当前线程是否已经获得了锁,这是前置条件。然后唤醒条件队列中的头节点。
1 2 3 4 5 6 7 8 9 10 private void doSignal (Node first) do { if ( (firstWaiter = first.nextWaiter) == null ) lastWaiter = null ; first.nextWaiter = null ; } while (!transferForSignal(first) && (first = firstWaiter) != null ); }
doSignal(Node first)主要是做两件事:
修改头节点;
调用transferForSignal(Node first) 方法将节点移动到CLH同步队列中。
整个通知的流程如下:
判断当前线程是否已经获取了锁,如果没有获取则直接抛出异常,因为获取锁为通知的前置条件。
如果线程已经获取了锁,则将唤醒条件队列的首节点。
唤醒首节点是先将条件队列中的头节点移出,然后调用AQS的enq(Node node)方法将其安全地移 到CLH同步队列中 。
最后判断如果该节点的同步状态是否为Cancel,或者修改状态为Signal失败时,则直接调用 LockSupport唤醒该节点的线程。
一个线程获取锁后,通过调用Condition的await()方法,会将当前线程先加入到条件队列中,然后释 放锁,后通过isOnSyncQueue(Node node)方法不断自检看节点是否已经在CLH同步队列了,如果是 则尝试获取锁,否则一直挂起。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class BoundedBuffer final Lock lock = new ReentrantLock(); final Condition notFull = lock.newCondition(); final Condition notEmpty = lock.newCondition(); final Object[] items = new Object[100 ]; int putptr, takeptr, count; public void put (Object x) throws InterruptedException lock.lock(); try { while (count == items.length) notFull.await(); items[putptr] = x; if (++putptr == items.length) putptr = 0 ; ++count; notEmpty.signal(); } finally { lock.unlock(); } } public Object take () throws InterruptedException lock.lock(); try { while (count == 0 ) notEmpty.await(); Object x = items[takeptr]; if (++takeptr == items.length) takeptr = 0 ; --count; notFull.signal(); return x; } finally { lock.unlock(); } } }
3.4 Synchronizers 3.4.1 Semaphore Semaphore(信号量)是用来控制同时访问特定资源的线程数量,通过协调各个线程,保证合理的使用 公共资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Semaphore;class PrintQueue private final Semaphore semaphore; public PrintQueue () semaphore = new Semaphore(1 ); } public void printJob (Object document) try { semaphore.acquire(); long duration = (long ) (Math.random() * 10 ); System.out.printf("%s: PrintQueue: Printing a Job during %d seconds\n" , Thread.currentThread().getName(), duration); Thread.sleep(duration); } catch (InterruptedException e) { e.printStackTrace(); } finally { semaphore.release(); } } } class Job implements Runnable private PrintQueue printQueue; public Job (PrintQueue printQueue) this .printQueue = printQueue; } @Override public void run () System.out.printf("%s: Going to print a job\n" , Thread.currentThread().getName()); printQueue.printJob(new Object()); System.out.printf("%s: The document has been printed\n" , Thread.currentThread().getName()); } } public class SemaphoreTest public static void main (String args[]) PrintQueue printQueue = new PrintQueue(); Thread thread[] = new Thread[10 ]; for (int i = 0 ; i < 10 ; i++) { thread[i] = new Thread(new Job(printQueue), "Thread" + i); } for (int i = 0 ; i < 10 ; i++) { thread[i].start(); } } }
3.4.2 CountDownLatch 在多线程协作完成业务功能时,有时候需要等待其他多个线程完成任务之后,主线程才能继续往下执行业务功能,在这种的业务场景下,通常可以使用Thread类的join方法,让主线程等待被join的线程执 行完之后,主线程才能继续往下执行。当然,使用线程间消息通信机制也可以完成。其实,java并发工 具类中为我们提供了类似“倒计时”这样的工具类,可以十分方便的完成所说的这种业务场景。
public CountDownLatch(int count) 构造方法会传入一个整型数N,之后调用 CountDownLatch的 countDown 方法会对N减一,知道N减到0的时候,当前调用 await 方法的线程继续执行。
await() throws InterruptedException:调用该方法的线程等到构造方法传入的N减到0的时候,才能继续往下执行;
await(long timeout, TimeUnit unit):与上面的await方法功能一致,只不过这里有了时间 限制,调用该方法的线程等到指定的timeout时间后,不管N是否减至为0,都会继续往下执行;
countDown():使CountDownLatch初始值N减1;
long getCount():获取当前CountDownLatch维护的值
栗子:运动员进行跑步比赛时,假设有6个运动员参与比赛,裁判员在终点会为这6个运动员分别计时, 可以想象没当一个运动员到达终点的时候,对于裁判员来说就少了一个计时任务。直到所有运动员都到 达终点了,裁判员的任务也才完成。这6个运动员可以类比成6个线程,当线程调用 CountDownLatch.countDown方法时就会对计数器的值减一,直到计数器的值为0的时候,裁判员(调 用await方法的线程)才能继续往下执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class CountDownLatchTest private static CountDownLatch startSignal = new CountDownLatch(1 ); rivate static CountDownLatch endSignal = new CountDownLatch(6 ); public static void main (String[] args) throws InterruptedException ExecutorService executorService = Executors.newFixedThreadPool(6 ); for (int i = 0 ; i < 6 ; i++) { executorService.execute(() -> { try { System.out.println(Thread.currentThread().getName() + " 运动 员等待裁判员响哨!!!" ); startSignal.await(); System.out.println(Thread.currentThread().getName() + "正在 全力冲刺" ); endSignal.countDown(); System.out.println(Thread.currentThread().getName() + " 到 达终点" ); } catch (InterruptedException e) { e.printStackTrace(); } }); } System.out.println("裁判员响哨开始啦!!!" ); startSignal.countDown(); endSignal.await(); System.out.println("所有运动员到达终点,比赛结束!" ); executorService.shutdown(); } }
该示例代码中设置了两个CountDownLatch,第一个endSignal用于控制让main线程(裁判员)必须等 到其他线程(运动员)让CountDownLatch维护的数值N减到0为止,相当于一个完成信号;另一个 startSignal用于让main线程对其他线程进行“发号施令”,相当于一个入口或者开关。
startSignal引用的CountDownLatch初始值为1,而其他线程执行的run方法中都会先通过 startSignal.await()让这些线程都被阻塞,直到main线程通过调用startSignal.countDown();, 将值N减1,CountDownLatch维护的数值N为0后,其他线程才能往下执行,并且,每个线程执行的run 方法中都会通过endSignal.countDown();对endSignal维护的数值进行减一,由于往线程池提交了6 个任务,会被减6次,所以endSignal维护的值终会变为0,因此main线程在latch.await();阻塞结 束,才能继续往下执行。
注意:当调用CountDownLatch的countDown方法时,当前线程是不会被阻塞,会继续往下执行。
3.4.3 CyclicBarrier CountDownLatch是一个倒数计数器,在计数器不为0时,所有调用await的线程都会等待,当计数器降 为0,线程才会继续执行,且计数器一旦变为0,就不能再重置了。
CyclicBarrier可以认为是一个栅栏,栅栏的作用是什么?就是阻挡前行。
CyclicBarrier是一个可以循环使用的栅栏,它做的事情就是:让线程到达栅栏时被阻塞(调用await 方法),直到到达栅栏的线程数满足指定数量要求时,栅栏才会打开放行,被栅栏拦截的线程才可以执行。
当多个线程都达到了指定点后,才能继续往下继续执行。这就有点像报数的感觉,假设6个线程就相当 于6个运动员,到赛道起点时会报数进行统计,如果刚好是6的话,这一波就凑齐了,才能往下执行。这 里的6个线程,也就是计数器的初始值6,是通过CyclicBarrier的构造方法传入的。
CyclicBarrier的主要方法:
await() throws InterruptedException, BrokenBarrierException 等到所有的线程都到 达指定的临界点;
await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutException 与上面的await方法功能基本一致,只不过这 里有超时限制,阻塞等待直至到达超时时间为止;
int getNumberWaiting()获取当前有多少个线程阻塞等待在临界点上;
boolean isBroken()用于查询阻塞等待的线程是否被中断
void reset()将屏障重置为初始状态。如果当前有线程正在临界点等待的话,将抛出 BrokenBarrierException。
另外需要注意的是,CyclicBarrier提供了这样的构造方法:
1 public CyclicBarrier (int parties, Runnable barrierAction)
可以用来,当指定的线程都到达了指定的临界点的时,接下来执行的操作可以由barrierAction传入即 可。
栗子:
6个运动员准备跑步比赛,运动员在赛跑需要在起点做好准备,当裁判发现所有运动员准备完毕后,就 举起发令枪,比赛开始。这里的起跑线就是屏障,是临界点,而这6个运动员就类比成线程的话,就是 这6个线程都必须到达指定点了,意味着凑齐了一波,然后才能继续执行,否则每个线程都得阻塞等待,直至凑齐一波即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class CyclicBarrierTest public static void main (String[] args) int N = 6 ; CyclicBarrier cb = new CyclicBarrier(N, new Runnable() { @Override public void run () System.out.println("所有运动员已准备完毕,发令枪:跑!" ); } }); for (int i = 0 ; i < N; i++) { Thread t = new Thread(new PrepareWork(cb), "运动员[" + i + "]" ); t.start(); } } private static class PrepareWork implements Runnable private CyclicBarrier cb; PrepareWork(CyclicBarrier cb) { this .cb = cb; } @Override public void run () try { Thread.sleep(500 ); System.out.println(Thread.currentThread().getName() + ": 准 备完成" ); cb.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } } } }
从输出结果可以看出,当6个运动员(线程)都到达了指定的临界点(barrier)时候,才能继续往下 执行,否则,则会阻塞等待在调用 await() 处。
CyclicBarrier对异常的处理 线程在阻塞过程中,可能被中断,那么既然CyclicBarrier放行的条件是等待的线程数达到指定数目, 万一线程被中断导致终的等待线程数达不到栅栏的要求怎么办?
1 2 3 public int await () throws InterruptedException, BrokenBarrierException }
可以看到,这个方法除了抛出InterruptedException异常外,还会抛出 BrokenBarrierException 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class CyclicBarrierTest public static void main (String[] args) throws InterruptedException int N = 6 ; CyclicBarrier cb = new CyclicBarrier(N, new Runnable() { @Override public void run () System.out.println("所有运动员已准备完毕,发令枪:跑!" ); } }); List<Thread> list = new ArrayList<>(); for (int i = 0 ; i < N; i++) { Thread t = new Thread(new PrepareWork(cb), "运动员[" + i + "]" ); list.add(t); t.start(); if (i == 3 ) { t.interrupt(); } } Thread.sleep(2000 ); System.out.println("Barrier是否损坏:" + cb.isBroken()); } private static class PrepareWork implements Runnable private CyclicBarrier cb; PrepareWork(CyclicBarrier cb) { this .cb = cb; } @Override public void run () try { System.out.println(Thread.currentThread().getName() + ": 准 备完成" ); cb.await(); } catch (InterruptedException e) { System.out.println(Thread.currentThread().getName() + ": 被 中断" ); } catch (BrokenBarrierException e) { System.out.println(Thread.currentThread().getName() + ": 抛 出BrokenBarrierException" ); } } } }
CountDownLatch与CyclicBarrier的比较
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而 CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行; CountDownLatch强调一个线程等多个线程完成某件事情。CyclicBarrier是多个线程互等,等大 家都完成,再携手共进。
调用CountDownLatch的countDown方法后,当前线程并不会阻塞,会继续往下执行;而调用 CyclicBarrier的await方法,会阻塞当前线程,直到CyclicBarrier指定的线程全部都到达了 指定点的时候,才能继续往下执行;
CountDownLatch方法比较少,操作比较简单,而CyclicBarrier提供的方法更多,比如能够通过 getNumberWaiting(),isBroken()这些方法获取当前多个线程的状态,并且CyclicBarrier的 构造方法可以传入barrierAction,指定当所有线程都到达时执行的业务功能;
CountDownLatch是不能复用的,而CyclicLatch是可以复用的。
3.4.4 Exchanger Exchanger可以用来在两个线程之间交换持有的对象。当Exchanger在一个线程中调用exchange方法之 后,会等待另外的线程调用同样的exchange方法,两个线程都调用exchange方法之后,传入的参数就 会交换。
栗子:
然后定义两个Runnable,在run方法中调用exchange方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class ExchangerTest public static void main (String[] args) Exchanger<CustBook> exchanger = new Exchanger<>(); new Thread(new ExchangerOne(exchanger)).start(); new Thread(new ExchangerTwo(exchanger)).start(); } } public class CustBook private String name; } public class ExchangerOne implements Runnable Exchanger<CustBook> ex; ExchangerOne(Exchanger<CustBook> ex){ this .ex=ex; } @Override public void run () CustBook custBook= new CustBook(); custBook.setName("book one" ); try { CustBook exhangeCustBook=ex.exchange(custBook); log.info(exhangeCustBook.getName()); } catch (InterruptedException e) { e.printStackTrace(); } } } public class ExchangerTwo implements Runnable Exchanger<CustBook> ex; ExchangerTwo(Exchanger<CustBook> ex){ this .ex=ex; } @Override public void run () CustBook custBook= new CustBook(); custBook.setName("book two" ); try { CustBook exhangeCustBook=ex.exchange(custBook); log.info(exhangeCustBook.getName()); } catch (InterruptedException e) { e.printStackTrace(); } } }
3.4.5 Phaser Phaser是一个同步工具类,适用于一些需要分阶段的任务的处理。它的功能与 CyclicBarrier和 CountDownLatch类似,类似于一个多阶段的栅栏,并且功能更强大,我们来比较下这三者的功能:
CountDownLatch 倒数计数器,初始时设定计数器值,线程可以在计数器上等待,当计数器 值归0后,所有等待的线程继续执行
CyclicBarrier 循环栅栏,初始时设定参与线程数,当线程到达栅栏后,会等待其它线程的到达,当到达栅栏的总数满足指定数后,所有等待的线程继续执行
Phaser 多阶段栅栏,可以在初始时设定参与线程数,也可以中途注册/注销参与 者,当到达的参与者数量满足栅栏设定的数量后,会进行阶段升级 (advance)
相关概念:
phase(阶段)
Phaser也有栅栏,在Phaser中,栅栏的名称叫做phase(阶段),在任意时间点,Phaser只处于某一个 phase(阶段),初始阶段为0,大达到Integerr.MAX_VALUE,然后再次归零。当所有parties参与者 都到达后,phase值会递增。
parties(参与者)
Phaser既可以在初始构造时指定参与者的数量,也可以中途通过register、bulkRegister、 arriveAndDeregister等方法注册/注销参与者。
arrive(到达) / advance(进阶)
Phaser注册完parties(参与者)之后,参与者的初始状态是unarrived的,当参与者到达 (arrive)当前阶段(phase)后,状态就会变成arrived。当阶段的到达参与者数满足条件后(注册 的数量等于到达的数量),阶段就会发生进阶(advance)——也就是phase值+1。
Termination(终止)
代表当前Phaser对象达到终止状态。
Tiering(分层)
Phaser支持分层(Tiering) —— 一种树形结构,通过构造函数可以指定当前待构造的Phaser对象 的父结点。之所以引入Tiering,是因为当一个Phaser有大量参与者(parties)的时候,内部的同步 操作会使性能急剧下降,而分层可以降低竞争,从而减小因同步导致的额外开销。
arriveAndDeregister() 该方法立即返回下一阶段的序号,并且其它线程需要等待的个数减 一, 取消自己的注册、把当前线程从之后需要等待的成员中移除。 如果该Phaser是另外一个Phaser的子Phaser(层次化Phaser), 并且该操作导致当前Phaser的成员数为0,则该操作也会将当前Phaser从其父Phaser中移除。
arrive() 某个参与者完成任务后调用,该方法不作任何等待,直接返回下一阶段的序号。
awaitAdvance(int phase) 该方法等待某一阶段执行完毕。 如果当前阶段不等于指定的阶段或者该Phaser已经被终止,则立即返回。 该阶段数一般由arrive()方法或者arriveAndDeregister()方法返回。 返回下一阶段的序号,或者返回参数指定的值(如果该参数为负数),或者直接返回当前阶 段序号(如果当前Phaser已经被终止)。
awaitAdvanceInterruptibly(int phase) 效果与awaitAdvance(int phase)相当, 唯一的不同在于若该线程在该方法等待时被中断,则该方法抛出InterruptedException。
awaitAdvanceInterruptibly(int phase, long timeout, TimeUnit unit) 效果与awaitAdvanceInterruptibly(int phase)相当,区别在于如果超时则抛出TimeoutException。
bulkRegister(int parties) 动态调整注册任务parties的数量。如果当前phaser已经被终 止,则该方法无效,并返回负数。 如果调用该方法时,onAdvance方法正在执行,则该方法等待其执行完毕。 如果该Phaser有父Phaser则指定的party数大于0,且之前该Phaser的party数为0,那么该 Phaser会被注册到其父Phaser中。
forceTermination() 强制让该Phaser进入终止状态。 已经注册的party数不受影响。如果该Phaser有子Phaser,则其所有的子Phaser均进入终止 状态。如果该Phaser已经处于终止状态,该方法调用不造成任何影响。
栗子:3个线程,4个阶段,每个阶段都并发处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package kaikeba.com;import java.util.concurrent.Phaser;public class PhaserTest public static void main (String[] args) int parties = 3 ; int phases = 4 ; final Phaser phaser = new Phaser(parties) { @Override protected boolean onAdvance (int phase, int registeredParties) System.out.println("====== Phase : " + phase + " end ======" ); return registeredParties == 0 ; } }; for (int i = 0 ; i < parties; i++) { int threadId = i; Thread thread = new Thread(() -> { for (int phase = 0 ; phase < phases; phase++) { if (phase == 0 ) { System.out.println(String.format("第一阶段操作 Thread %s, phase %s" , threadId, phase)); } if (phase == 1 ) { System.out.println(String.format("第二阶段操作 Thread %s, phase %s" , threadId, phase)); } if (phase == 2 ) { System.out.println(String.format("第三阶段操作 Thread %s, phase %s" , threadId, phase)); } if (phase == 3 ) { System.out.println(String.format("第四阶段操作 Thread %s, phase %s" , threadId, phase)); } int nextPhaser = phaser.arriveAndAwaitAdvance(); } }); thread.start(); } } }
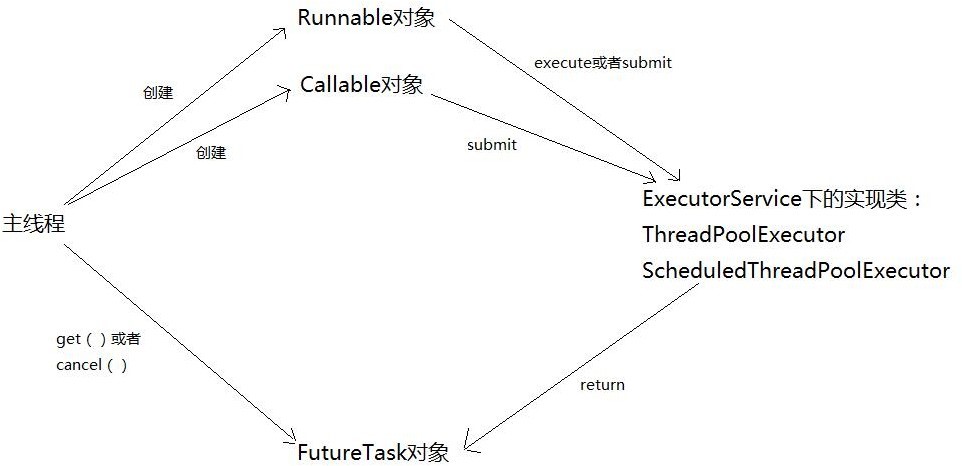
3.5 Executors 3.5.1 Executor框架 Executor框架包括3大部分:
任务。也就是工作单元,包括被执行任务需要实现的接口:Runnable接口或者Callable接口;
任务的执行。也就是把任务分派给多个线程的执行机制,包括Executor接口及继承自Executor接 口的ExecutorService接口。
异步计算的结果。包括Future接口及实现了Future接口的FutureTask类。
Executor框架的成员及其关系可以用一下的关系图表示:
Executor框架的使用示意图:
使用步骤:
创建Runnable并重写run()方法或者Callable对象并重写call()方法,得到一个任务对象
1 2 3 4 5 6 7 8 9 10 11 12 13 class callableImp implements Callable <String > @Override public String call () try { String a = "return String" ; return a; } catch (Exception e){ e.printStackTrace(); return "exception" ; } } }
创建ExecutorService接口的实现类ThreadPoolExecutor类或者 ScheduledThreadPoolExecutor类的对象,然后调用其execute()方法或者submit()方法,提 交任务对象执行。
主线程调用Future对象的get()方法获取返回值,或者调用Future对象的cancel()方法取消当前 线程的执行。
Executor框架成员:ThreadPoolExecutor实现类、ScheduledThreadPoolExecutor实现类、Future 接口、Runnable和Callable接口、Executors工厂类
Runnable和Callable接口:Runnable和Callable接口的实现类,可以被ThreadPoolExecutor和 ScheduledThreadPoolExecutor执行,区别是,亲着没有返回结果,候着可以返回结果。
3.5.2 ThreadPoolExecutor ThreadPoolExecutor一共提供了4种构造器,但其它三种内部其实都调用了下面的构造器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0 ) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null ) throw new NullPointerException(); this .corePoolSize = corePoolSize; this .maximumPoolSize = maximumPoolSize; this .workQueue = workQueue; this .keepAliveTime = unit.toNanos(keepAliveTime); this .threadFactory = threadFactory; this .handler = handler; }
线程池状态定义;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
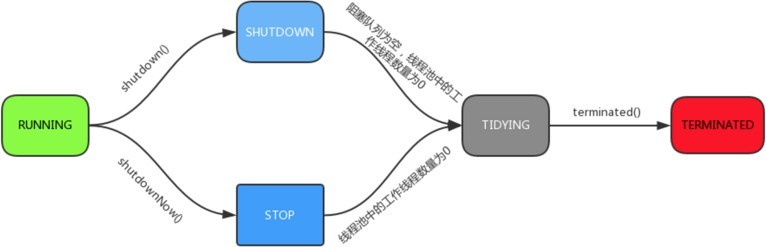
ThreadPoolExecutor一共定义了5种线程池状态:
RUNNING : 接受新任务, 且处理已经进入阻塞队列的任务
SHUTDOWN : 不接受新任务, 但处理已经进入阻塞队列的任务
STOP : 不接受新任务, 且不处理已经进入阻塞队列的任务, 同时中断正在运行的任务
TIDYING : 所有任务都已终止, 工作线程数为0, 线程转化为TIDYING状态并准备调用
terminated方法 TERMINATED : terminated方法已经执行完成
各个状态之间的流转图:
执行execute
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public void execute (Runnable command) if (command == null ) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true )) return ; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (!isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0 ) addWorker(null , false ); } else if (!addWorker(command, false )) reject(command); }
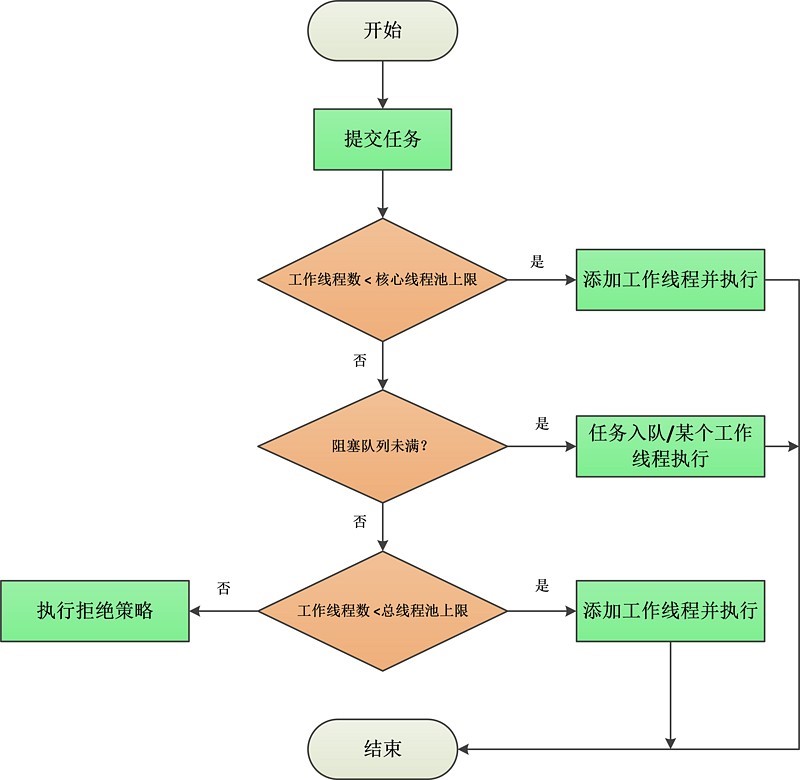
上述execute的执行流程可以用下图描述:
execute的整个执行流程关键是下面两点:
如果工作线程数小于核心线程池上限(CorePoolSize),则直接新建一个工作线程并执行任务;
如果工作线程数大于等于CorePoolSize,则尝试将任务加入到队列等待以后执行。如果加入队列 失败了(比如队列已满的情况),则在总线程池未满的情况下( CorePoolSize ≤ 工作线程数 < maximumPoolSize )新建一个工作线程立即执行任务,否则执行拒绝策略。
通过Executor框架的工具类Executors,可以创建三种类型的ThreadPoolExecutor:
1 2 3 4 5 public static ExecutorService newFixedThreadPool (int nThreads) return new ThreadPoolExecutor(nThreads, nThreads, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
newFixedThreadPool 创建一个固定长度的线程池,每次提交一个任务的时候就会创建一个新的线程, 直到达到线程池的大数量限制。
定长,可以控制线程大并发数, corePoolSize 和 maximumPoolSize 的数值都是 nThreads。
超出线程数的任务会在队列中等待。
工作队列为LinkedBlockingQueue
创建方法
1 ExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads);
SingleThreadExecutor:使用单个线程的Executor
1 2 3 4 5 6 7 public static ExecutorService newSingleThreadExecutor (ThreadFactory threadFactory) return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1 , 1 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory)); }
newSingleThreadExecutor ,只创建一个工作线程执行任务,若这个唯一的线程异常故障了,会新建 另一个线程来替代,newSingleThreadExecutor可以保证任务依照在工作队列的排队顺序来串行执 行。
有且仅有一个工作线程执行任务;
所有任务按照工作队列的排队顺序执行,先进先出的顺序
工作队列LinkedBlockingQueue
创建方法
1 ExecutorService singleThreadPool = Executors.newSingleThreadPool();
CachedThreadPool:会根据需要创建新线程的线程池
1 2 3 4 5 6 public static ExecutorService newCachedThreadPool (ThreadFactory threadFactory) return new ThreadPoolExecutor(0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), threadFactory); }
newCachedThreadPool 将创建一个可缓存的线程池,如果当前线程数超过处理任务时,回收空闲线 程;当需求增加时,可以添加新线程去处理任务。
线程数无限制,corePoolSize数值为0, maximumPoolSize 的数值都是为 Integer.MAX_VALUE。
若线程未回收,任务到达时,会复用空闲线程;
若无空闲线程,则新建线程执行任务。 因为复用性,一定程序减少频繁创建/销毁线程,减少系统开销。
工作队列选用SynchronousQueue。
创建方法
1 ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import java.io.IOException;import java.util.concurrent.*; import java.util.concurrent.atomic.AtomicInteger;public class ThreadPoolExecutorTest public static void main (String[] args) throws InterruptedException, IOException int corePoolSize = 2 ; int maximumPoolSize = 4 ; long keepAliveTime = 10 ; TimeUnit unit = TimeUnit.SECONDS; BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2 ); RejectedExecutionHandler handler = new RejectedExecutionPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler); executor.prestartAllCoreThreads(); for (int i = 1 ; i <= 10 ; i++) { ThreadTask task = new ThreadTask(String.valueOf(i)); executor.execute(task); } System.in.read(); } public static class RejectedExecutionPolicy implements RejectedExecutionHandler public void rejectedExecution (Runnable r, ThreadPoolExecutor e) doLog(r, e); } private void doLog (Runnable r, ThreadPoolExecutor e) System.err.println( r.toString() + " rejected" ); } } static class ThreadTask implements Runnable private String name; public ThreadTask (String name) this .name = name; } @Override public void run () try { System.out.println(this .toString() + " is running!" ); Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } } public String getName () return name; } @Override public String toString () return "ThreadTask [name=" + name + "]" ; } } }
3.5.3 ScheduledExecutorService 构造线程池
1 2 3 4 5 6 public static ScheduledExecutorService newScheduledThreadPool (int corePoolSize) return new ScheduledThreadPoolExecutor(corePoolSize); } public static ScheduledExecutorService newScheduledThreadPool (int corePoolSize, ThreadFactory threadFactory) return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory); }
ScheduledThreadPoolExecutor的构造器,内部其实都是调用了父类ThreadPoolExecutor的构造 器,这里比较特别的是任务队列的选择——DelayedWorkQueue。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public ScheduledThreadPoolExecutor (int corePoolSize) super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue()); } public ScheduledThreadPoolExecutor (int corePoolSize, ThreadFactory threadFactory) super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue(), threadFactory); } public ScheduledThreadPoolExecutor (int corePoolSize, RejectedExecutionHandler handler) super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue(), handler); } public ScheduledThreadPoolExecutor (int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler) super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue(), threadFactory, handler); }
线程池的调度
1 2 3 4 5 6 7 public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) { if (command == null || unit == null ) throw new NullPointerException(); RunnableScheduledFuture<?> t = decorateTask(command, new ScheduledFutureTask<Void>(command, null , triggerTime(delay, unit))); delayedExecute(t); return t; }
上述的decorateTask方法把Runnable任务包装成ScheduledFutureTask,用户可以根据自己的需要 覆写该方法:
1 2 3 protected <V> RunnableScheduledFuture<V> decorateTask (Runnable runnable, RunnableScheduledFuture<V> task) { return task; }
ScheduledFutureTask是RunnableScheduledFuture接口的实现类,任务通过period字段来表示任务 类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private class ScheduledFutureTask <V > extends FutureTask <V > implements RunnableScheduledFuture <V > private final long sequenceNumber; private long time; private final long period; int heapIndex; ScheduledFutureTask(Runnable r, V result, long ns) { super (r, result); this .time = ns; this .period = 0 ; this .sequenceNumber = sequencer.getAndIncrement(); } }
ScheduledThreadPoolExecutor中的任务队列——DelayedWorkQueue,保存的元素就是 ScheduledFutureTask。DelayedWorkQueue是一种堆结构,time小的任务会排在堆顶(表示早 过期),每次出队都是取堆顶元素,这样快到期的任务就会被先执行。如果两个 ScheduledFutureTask的time相同,就比较它们的序号——sequenceNumber,序号小的代表先被提 交,所以就会先执行。
schedule的核心是其中的delayedExecute方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private void delayedExecute (RunnableScheduledFuture<?> task) if (isShutdown()) reject(task); else { super .getQueue().add(task); if (isShutdown() && !canRunInCurrentRunState(task.isPeriodic()) && remove(task)) task.cancel(false ); else ensurePrestart(); } }
处理过程:
任务被提交到线程池后,会判断线程池的状态,如果不是RUNNING状态会执行拒绝策略;
然后,将任务添加到阻塞队列中,由于DelayedWorkQueue是无界队列,所以一定会add成功;
然后,会创建一个工作线程,加入到核心线程池或者非核心线程池;
1 2 3 4 5 6 7 8 9 10 void ensurePrestart () int wc = workerCountOf(ctl.get()); if (wc < corePoolSize) addWorker(null , true ); else if (wc == 0 ) addWorker(null , false ); }
最后,线程池中的工作线程会去任务队列获取任务并执行,当任务被执行完成后,如果该任务是周 期任务,则会重置time字段,并重新插入队列中,等待下次执行。
从队列中获取元素的方法:
对于核心线程池中的工作线程来说,如果没有超时设置( allowCoreThreadTimeOut == false ),则会使用阻塞方法take获取任务(因为没有超时限制,所以会一直等待直到队列中有 任务);如果设置了超时,则会使用poll方法(方法入参需要超时时间),超时还没拿到任务的 话,该工作线程就会被回收。
对于非工作线程来说,都是调用poll获取队列元素,超时取不到任务就会被回收。
栗子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import java.util.concurrent.*;public class ScheduledThreadPoolExecutorTest public static void main (String[] args) throws ExecutionException, InterruptedException ScheduledThreadPoolExecutorTest.scheduleWithFixedDelay(); ScheduledThreadPoolExecutorTest.scheduleAtFixedRate(); ScheduledThreadPoolExecutorTest.scheduleCaller(); ScheduledThreadPoolExecutorTest.scheduleRunable(); } static void scheduleWithFixedDelay () throws InterruptedException, ExecutionException ScheduledExecutorService executorService = new ScheduledThreadPoolExecutor(10 ); ScheduledFuture<?> result = executorService.scheduleWithFixedDelay(new Runnable() { public void run () System.out.println(System.currentTimeMillis()); } }, 5000 , 5000 , TimeUnit.MILLISECONDS); result.get(); System.out.println("over" ); } static void scheduleAtFixedRate () throws InterruptedException, ExecutionException ScheduledExecutorService executorService = new ScheduledThreadPoolExecutor(10 ); ScheduledFuture<?> result = executorService.scheduleAtFixedRate(new Runnable() { public void run () System.out.println(System.currentTimeMillis()); } }, 2000 , 5000 , TimeUnit.MILLISECONDS); result.get(); System.out.println("over" ); } static void scheduleRunable () throws InterruptedException, ExecutionException new ScheduledThreadPoolExecutor(10 ); ScheduledFuture<?> result = executorService.schedule(new Runnable() { @Override public void run () "gh" ); try { Thread.sleep(3000 ); } catch (InterruptedException e) { } }, 2000 , TimeUnit.MILLISECONDS); System.out.println(result.get()); } static void scheduleCaller () throws InterruptedException, ExecutionException ScheduledExecutorService executorService = new ScheduledThreadPoolExecutor(10 ); ScheduledFuture<String> result = executorService.schedule(new Callable<String>() { @Override public String call () throws Exception try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } return "gh" ; } }, 2000 , TimeUnit.MILLISECONDS); System.out.print(result.get()); } }